深度解读 RocketMQ 存储机制
在《阿里开发者》公众号看到这篇文章,深度解析了RocketMQ的存储机制,对理解RocketMQ存储原理及进行性能优化很有帮助。
原文地址:深度解读 RocketMQ 存储机制
RocketMQ 实现了灵活的多分区和多副本机制,有效的避免了集群内单点故障对于整体服务可用性的影响。存储机制和高可用策略是 RocketMQ 稳定性的核心,社区上关于 RocketMQ 目前存储实现的分析与讨论一直是一个热议的话题。本文想从一个不一样的视角,着重于谈谈我眼中的这种存储实现是在解决哪些复杂的问题,因此我从本文最初的版本中删去了冗杂的代码细节分析,由浅入深的分析存储机制的缺陷与优化方向。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 逐光の博客!
相关推荐

2023-03-10
RocketMQ 生死对决:从版本之争到云上之战(二)
在上一篇磨刀不误砍柴工:我们的硬件基准性能大摸底中,我们搞清楚了测试环境的硬件天花板。现在,让我们把主角请上场——Apache RocketMQ。 作为分布式系统的核心“动脉”,消息队列的选型直接关系到整个系统的稳定性和上限。这次,我们将对 RocketMQ 进行一次无死角的深度解剖,从不同硬件、不同版本,再到自建与云服务的终极对决,用数据说话,把它的性能、优劣、坑点一次性聊个透。 1. 硬件差异:闪存卡 vs. 高性能 SSD这三组摸高数据的系统配置并不一致(例如:闪存卡环境为 CPU:24核 内存:40G,SSD 环境为 CPU:8核 内存:16G,云组件为托管规格),因此不能仅凭 TPS 数字直接得出“SSD 全面优于闪存卡”的结论。更准确的说法是:RocketMQ 的吞吐与延迟同时受 I/O 形态 与 整机规格(CPU/内存/网络) 共同影响,做横向对比前必须把变量(刷盘策略、队列数、消息大小、并发等)尽可能对齐。 为了让结论可复现、可核对,下面把本次摸高测试的原始结果表格直接放出来。 1.1 自建 RocketMQ(闪存卡)摸高数据 ...

2021-09-05
RocketMQ中的Consumer及ConsumerGroup详解
一、基本概念消息消费者(Consumer)负责消费消息,一般是后台系统负责异步消费。一个消息消费者会从Broker服务器拉取消息、并将其提供给应用程序。从用户应用的角度而言提供了两种消费形式:拉取式消费、推动式消费。 消费者组(Consumer Group)同一类Consumer的集合,这类Consumer通常消费同一类消息且消费逻辑一致。消费者组使得在消息消费方面,实现负载均衡和容错的目标变得非常容易。要注意的是,消费者组的消费者实例必须订阅完全相同的Topic。RocketMQ 支持两种消息模式:集群消费(Clustering)和广播消费(Broadcasting)。 集群消费(Clustering)集群消费模式下,相同Consumer Group的每个Consumer实例平均分摊消息。 广播消费(Broadcasting)广播消费模式下,相同Consumer Group的每个Consumer实例都接收全量的消息。 二、订阅关系一致订阅关系一致指的是同一个消费者Group ID下所有Consumer实例所订阅的Topic、Tag必须完全一致。如果订阅关系不一致,消息消费的逻辑...

2023-05-08
Kube-Prometheus监控RocketMQ(四)
一、概述本文介绍如何使用 Kube-Prometheus 监控 RocketMQ。通过部署 RocketMQ Exporter,将 RocketMQ 的消息队列指标暴露给 Prometheus 进行采集和监控。 核心组件: RocketMQ Exporter:用于暴露 RocketMQ 指标的 Exporter ServiceMonitor:Prometheus Operator 的 CRD,用于服务发现和指标采集配置 二、部署 RocketMQ Exporter2.1 创建 Deployment通过 Deployment 部署 RocketMQ Exporter,需要配置 NameServer 地址。 apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/component: exporter app.kubernetes.io/name: rocketmq-exporter app.kubernetes.io/part-of: kube-prometheus ...
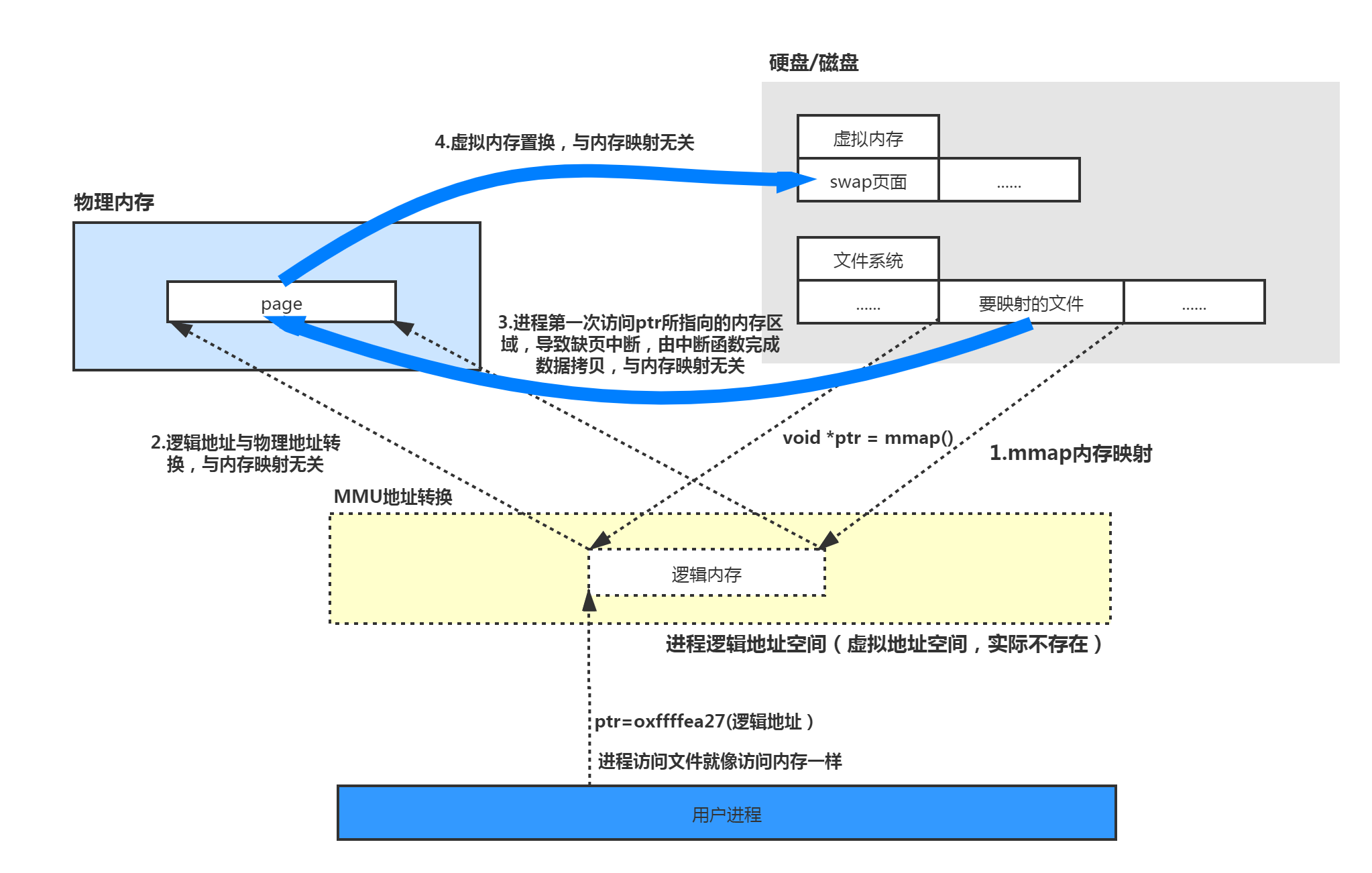
2020-10-29
RocketMQ中Mmap原理分析及使用
一、Mmap基础概念Mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。 二、Mmap内存映射原理 mmap内存映射的实现过程,总的来说可以分为三个阶段: (一)进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域 1、进程在用户空间调用库函数mmap,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset); 2、在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址 3、为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化 4、将新建的虚拟区结构(vm_area_s...
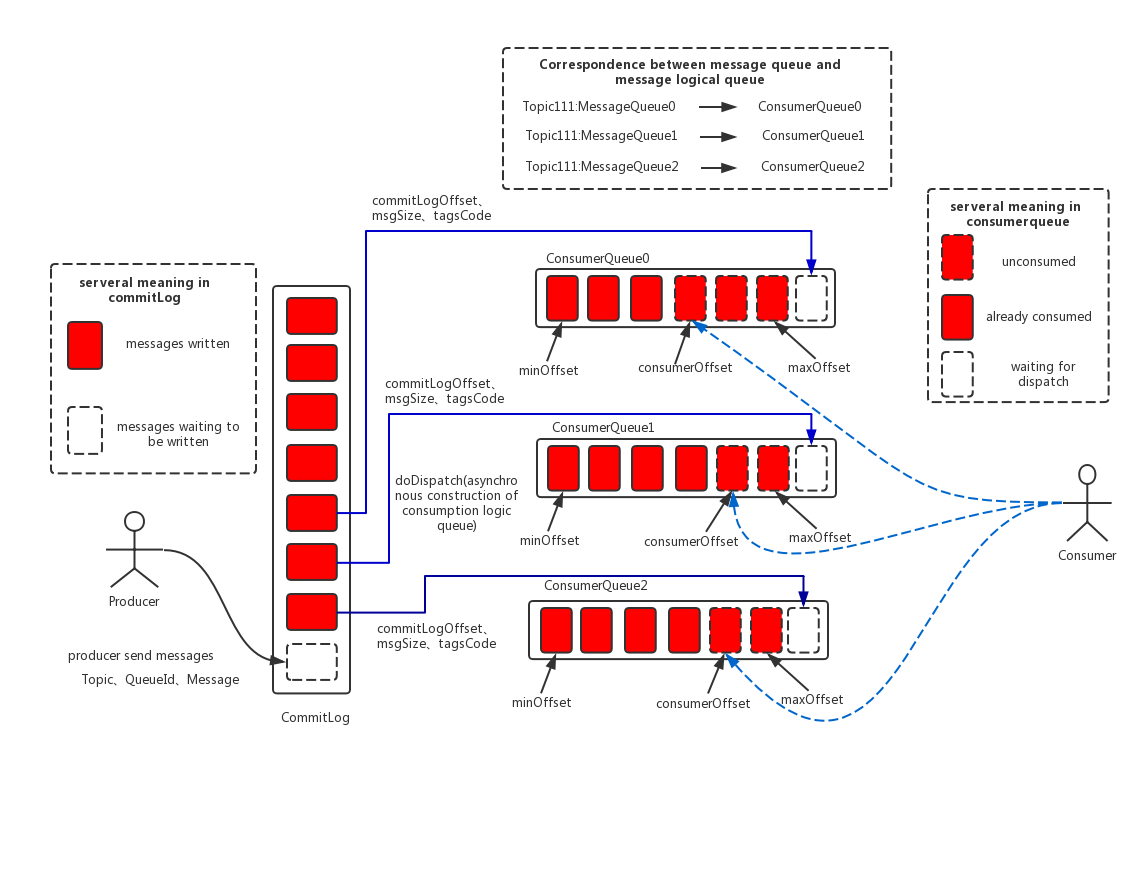
2020-09-10
RocketMQ消息存储
一、消息存储架构图 二、消息存储2.1 消息存储文件 文件名称 作用 文件大小 文件格式 说明 CommitLog 消息主体以及元数据的存储主体 单个文件大小默认1G 消息顺序写入文件,当文件满了,写入下一个文件 文件名为20位,如一个文件名为00000000000000000000代表以一个文件,起始偏移量为0,文件大小为1G=1073741824,后面新增文件的名称基于上一个文件名累加1G,起始偏移量从上一个文件继续累计。 ConsumeQueue 消息消费队列 每个条目20个字节,单个文件由30W个条目组成 每一个条目共20个字节,分别为8字节的commitlog物理偏移量、4字节的消息长度、8字节tag hashcode 单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个ConsumeQueue文件大小约5.72M IndexFile 索引文件 固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引 IndexFile的底层存储设计为在文件系统中实现HashMap结构 rocketmq...

2020-11-26
RocketMQ设计原理分析
RocketMQ设计原理分析——技术分享PPT 您的浏览器不支持显示PDF文件 📥 点击这里下载PDF文件
评论