Redis 缓存加速:自建的“小钢炮”能否抗衡云的“正规军”?(三)
在上一篇RocketMQ 生死对决:从版本之争到云上之战中,我们见证了 RocketMQ 的激烈对决。现在,让我们转向另一个在后端架构中几乎无处不在的“神器”——Redis。
作为高性能缓存的代名词,Redis 以其闪电般的速度和丰富的数据结构,成为提升应用性能的“银弹”。但当我们将它部署在云上时,同样面临那个经典的选择:是在云主机上自建一个 Redis 集群,还是直接使用云厂商提供的托管缓存服务(如华为云的 DCS for Redis)?
这次,我们将深入细节,看看自建的“小钢炮”和云上的“正规军”掰手腕,到底谁的功力更深厚。
1. 性能基准:自建 Redis vs. 华为云 DCS
本小节数据来自 redis-benchmark 的同口径压测结果(消息大小、并发数、请求量一致),其中自建为 3主3从 集群,云组件为 6主6从 集群(两边单分片内存配置均为 8G)。
核心性能数据对比(节选,消息大小 1024 bytes):
| 并发连接数 | 自部署 SET(req/s) | 自部署 GET(req/s) | 云组件 SET(req/s) | 云组件 GET(req/s) |
|---|---|---|---|---|
| 100 | 78,419.07 | 81,619.33 | 333,222.28 | 400,000.00 |
| 150 | 111,098.77 | 117,647.06 | 399,840.06 | 499,750.16 |
| 200 | 133,315.56 | 142,836.73 | 444,444.44 | 571,428.56 |
数据解读:
- 吞吐量 (QPS):在该组样本里,云组件的 SET 吞吐大约是自建的
3.33x ~ 4.25x,GET 吞吐大约是4.00x ~ 4.90x。 - 可比性边界:两边集群规模不同(
3主3从vs6主6从),这意味着云组件在“堆硬件/堆资源”维度天然更有优势。这个结果更像是在回答:当你需要把吞吐做上去时,云组件能把“扩容”这件事做得有多省心。
2. 持久化机制的“坑”:fork 操作的代价
Redis 的 RDB 持久化机制(BGSAVE)依赖于操作系统的 fork 系统调用来创建一个子进程。fork 需要拷贝父进程的内存页表,虽然有写时复制(Copy-on-Write)的优化,但在 Redis 实例占用内存较大(例如几十 GB)时,这个拷贝过程依然会导致主进程的短暂阻塞。
这个机制意味着:只要你依赖 RDB / AOF 的后台持久化,且实例内存足够大,就需要把“持久化引入的延迟抖动”纳入容量与压测口径中。云组件是否能把这个抖动做得更平滑,取决于其具体实现与调度策略,需要用业务自己的 SLA 指标(P99/P999、长尾尖刺频率等)做回归验证。
3. 运维复杂性:看不见的成本
除了性能,自建 Redis 还意味着你需要一个专业的团队来处理以下这些复杂的运维工作:
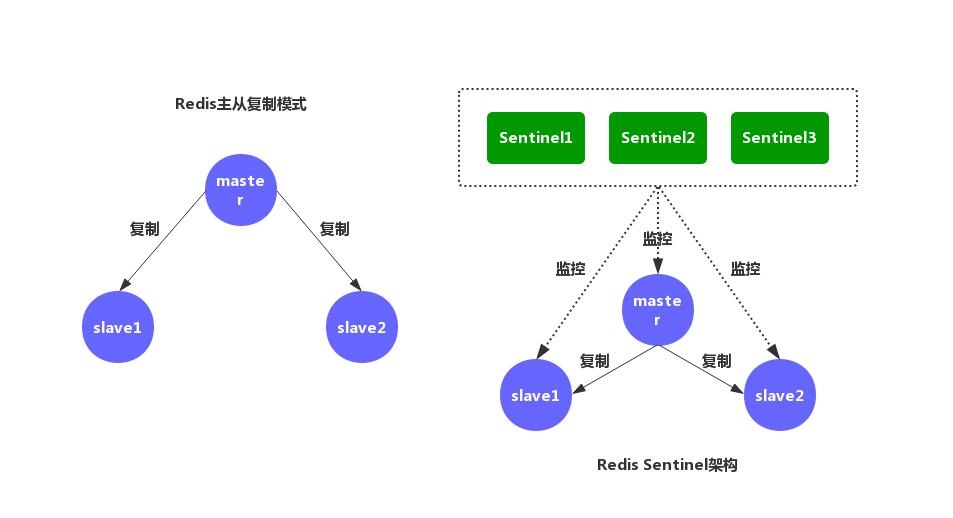
- 高可用部署:手动配置和维护 Sentinel(哨兵)集群,确保主节点故障时能自动切换。
- 集群扩展:当业务量增长时,需要手动进行集群的分片(Sharding)和数据迁移,这是一个高风险且复杂的操作。
- 版本升级:需要制定详细的升级计划,在业务低峰期进行滚动升级,并时刻准备回滚。
- 监控与告警:需要部署和配置完善的监控系统(如 Prometheus + Exporter),来监控 Redis 的各项关键指标。
而所有这些,在云服务中都只是几次鼠标点击,或者几行 API 调用。云服务将这些复杂的运维工作“黑盒化”,让你能更专注于业务逻辑本身。
本篇小结
通过对 Redis 的深度对比,我们发现:
- 吞吐量优势:在本次
redis-benchmark口径下,云组件的吞吐显著高于自建集群。 - 运维优势:云服务最大的价值,在于将你从复杂、繁琐的运维工作中解放出来。
到此,我们已经分别剖析了 RocketMQ 和 Redis。下一个篇章,我们将进入一个更有趣的领域——对象存储。在那里,我们会重点讨论如何利用自建方案,为云服务打造一个高性价比的“备胎”容灾体系。