生产应用日志监控告警方案
一、背景简介
生产之前出现过许多业务异常的情况未能及时发现,这些异常出现时有大量的异常日志打印,但是由于缺乏日志监控,未能及时发现异常并进行处理。
该方案计划对生产所有的异常日志进行监控及告警配置,及时发现生产日志异常,快速响应处理。
二、日志及监控采集方案
生产的日志采集和监控均基于Promtail组件实现,具体的原理如下:
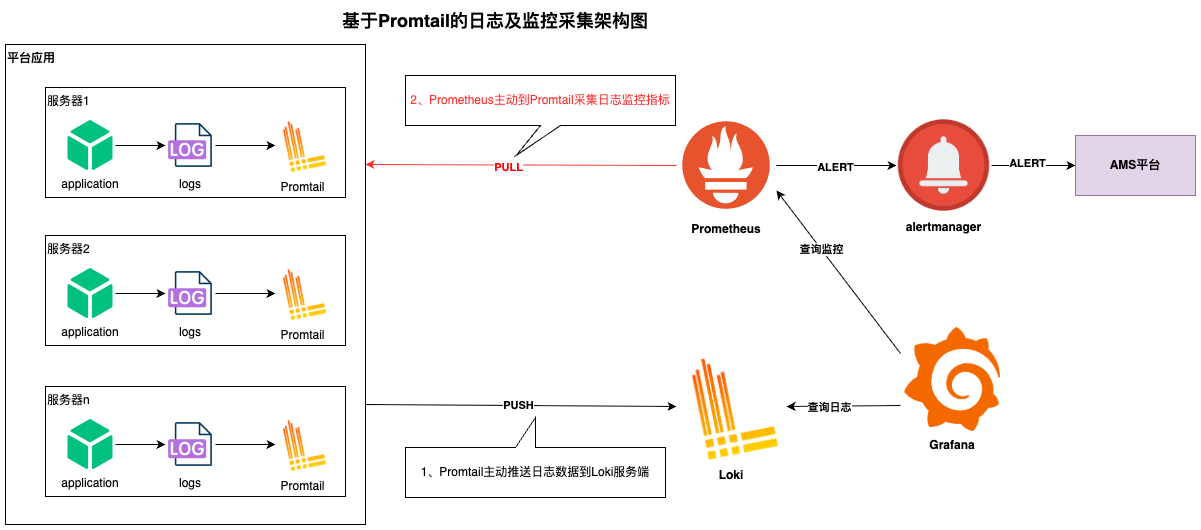
图:基于Promtail的日志和日志监控采集架构
2.1. 日志监控两种实现方式对比
日志监控两种实现方式包括:Promtail 中的 metrics 阶段和 Loki 的 ruler 组件。
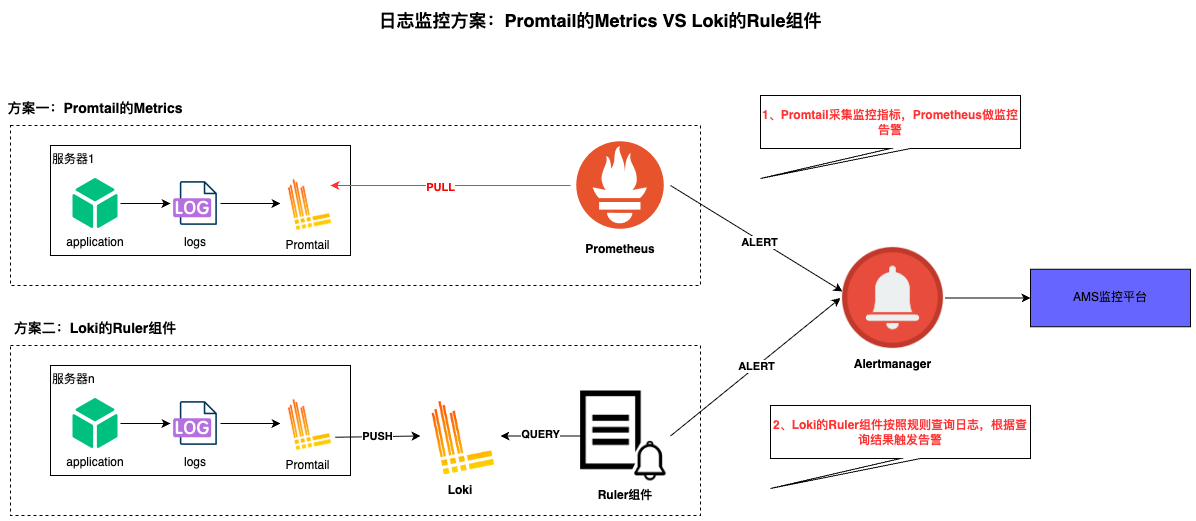
图:Promtail的Metrics VS Loki的Rule组件对比
总结:从性能和及时性综合评估,生产环境使用方案一更适合。
三、日志采集配置
生产环境目前所有应用均已实现基于Promtail的日志采集,但是有虚拟机和K8s容器环境两种区别。
3.1. 虚拟机日志采集配置
虚拟机进行日志采集时,上传Promtail组件到服务器,然后配置Promtail的配置文件:
config.yaml配置示例:
#promtail当作一个服务端,Prometheus通过该服务抓取监控指标
server:
http_listen_port: 9080
grpc_listen_port: 0
#2.7.2版本增加的从新加载配置文件的配置,可以访问:http://ip:9080/reload来从新加载配置文件
enable_runtime_reload: true
clients:
#需要推送给的Loki服务端的地址,可以配置多个,同时朝向多个Loki推送日志
- url: http://loki.example.com:30669/loki/api/v1/push
positions:
#Promtail采集到日志的时候,会把已经发送给Loki成功的日志的字节偏移量记录到这个文件当中
filename: ./positions.yaml
target_config:
#这个是同步采集的target的file的监控的的时间,默认也是10s
sync_period: 10s
scrape_configs:
- job_name: node-system-log
static_configs:
- targets:
- localhost
labels:
node: app-node
job: node-system-log
type: system
__path__: /var/log/syslog
- job_name: pod-logs #job的名字,可以在loki上面搜索条件:job="pod-logs"
kubernetes_sd_configs:
- role: pod3.1.1. 启动命令
nohup ./promtail-linux-amd64 -config.file=./config.yaml > promtail.log 2>&1 &Promtail启动后会根据配置文件config.yaml中的配置的__path__路径,监听路径下文件,采集上报至Loki。
3.2. k8s容器日志采集配置
在容器环境中,Promtail采用DaemonSet的部署,采集Pod中的日志信息。
DaemonSet 的典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
DaemonSet中通过configMap配置Promtail的配置文件。
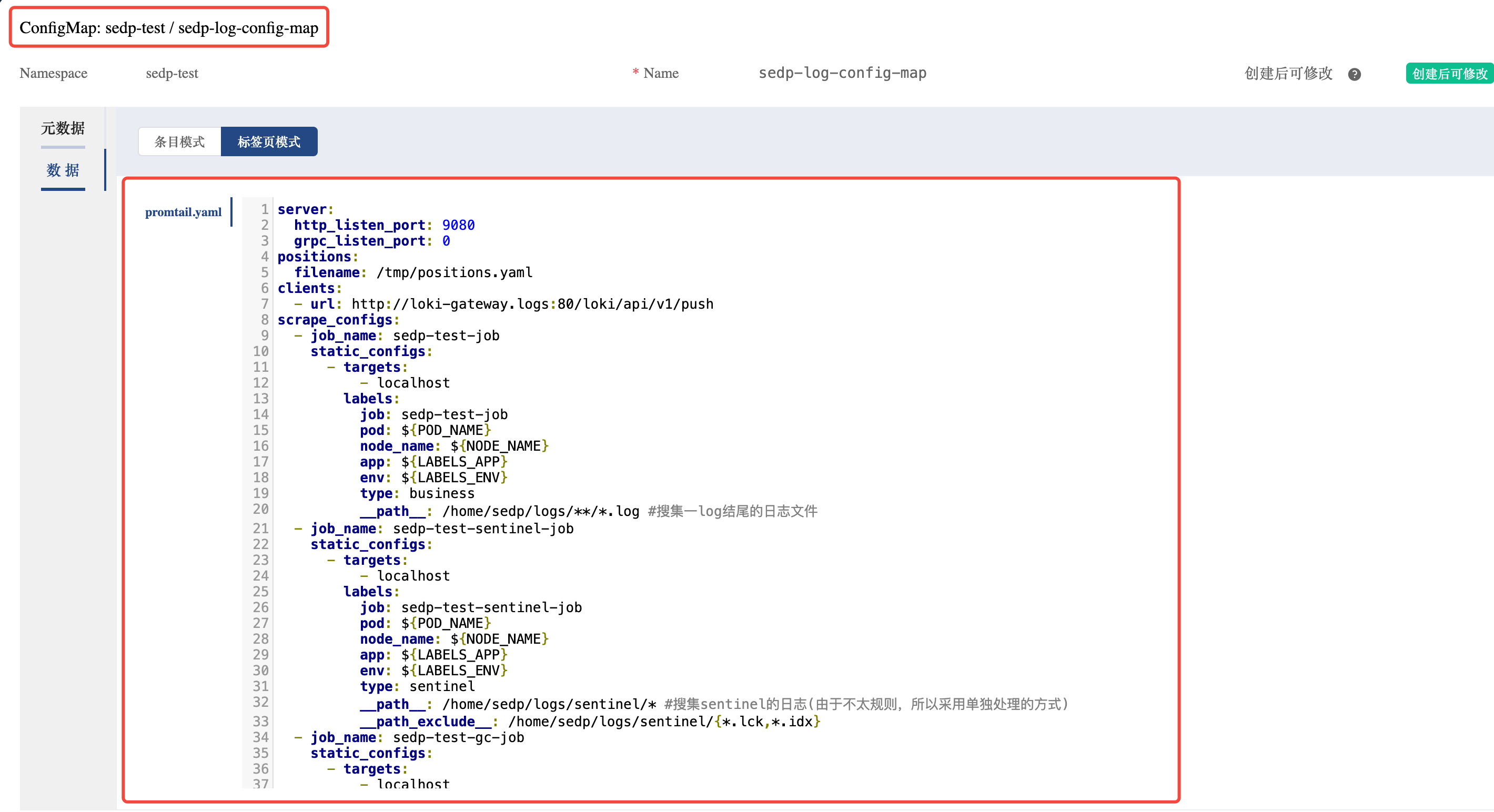
图:K8s环境中DaemonSet部署Promtail的架构示意
四、日志监控配置
在第三章节中,介绍了Promtail日志采集的配置,这个章节介绍如果配置日志监控。
4.1. 日志监控原理
Promtail的日志监控基于Pipeline实现,Promtail的Pipeline其实就是用来对一行日志执行操作的流水线,由统称为stages(阶段)这个专业术语来组成的。
官网地址:https://grafana.com/docs/loki/latest/send-data/promtail/stages/
日志监控主要基于Promtail Pipeline的regex和metrics两个stage:
- regex:使用正则提取数据
- metrics:根据提取的数据监控指标
图:Promtail Pipeline的日志处理流程
4.2. 日志监控配置说明
Promtail Pipeline各个State的变量是可以被用于下个Stage的,日志监控主要基于Regex和Metrics两个Stage配置实现。
4.2.1. Regex Stage配置说明
regex Stage主要用于从日志中提取数据,提取数据使用RE2 正则表达式。
官网地址:https://grafana.com/docs/loki/latest/send-data/promtail/stages/regex/
regex:
# The RE2 regular expression. Each capture group must be named.
expression: <string>
# Name from extracted data to parse. If empty, uses the log message.
[source: <string>]RE2正则语法官方文档:https://github.com/google/re2/wiki/Syntax
4.2.2. Metrics Stage配置说明
Metrics Stage主要用于定义监控指标名称、类型、采集次数。
官网地址:https://grafana.com/docs/loki/latest/send-data/promtail/stages/metrics/
metrics:
http_get_total:
type: Counter #Counter类型,参看Prometheus的四种指标类型
description: <string> #描述信息
prefix: <string> #指标的前缀,默认是:promtail_custom_,例如:promtail_custom_http_get_total
source: <string> #从提取数据中获取到的Key作为统计的指标来源,如果不提供,就是指标名字
max_idle_duration: <string> #指标的存活时间,避免出现业务上的指标的积累的问题,默认是:5m
config:
match_all: <bool> #如果设置为true,那么所有的日志行都会被统计到
count_entry_bytes: <bool> #如果设置为true,那么所有的日志行的bytes都会被统计
value: <string> #只有符合value的才会被统计,和match_all还有count_entry_bytes有一定的配置冲突
action: <string> #inc 或者 add这俩递增的意思。4.3. 日志监控配置示例
下面为一个日志监控指标示例,指标名为:data_truncation_total, 指标类型为:Counter,该指标对日志行内容包含”Data truncation”字符计数,该关键字在日志中每出现一次,指标值加1。
server:
http_listen_port: 9080
grpc_listen_port: 0
enable_runtime_reload: true
clients:
- url: http://loki.example.com:30669/loki/api/v1/push
positions:
filename: ./positions.yaml
target_config:
sync_period: 10s
scrape_configs:
- job_name: app-logs
static_configs:
- targets:
- localhost
labels:
job: app-logs
__path__: /var/log/app/*.log
pipeline_stages:
- regex:
expression: '.*(?P<error_content>Data truncation).*'
- metrics:
data_truncation_total:
type: Counter
description: "Count of data truncation errors"
config:
value: "{{.error_content}}"
action: inc五、告警配置
基于Promtail采集的日志监控指标,可以在Prometheus中配置相应的告警规则:
groups:
- name: log_alerts
rules:
- alert: DataTruncationAlert
expr: increase(promtail_custom_data_truncation_total[5m]) > 0
for: 0m
labels:
severity: warning
annotations:
summary: "检测到数据截断错误"
description: "在过去5分钟内检测到 {{ $value }} 次数据截断错误"总结
本方案通过Promtail实现了生产环境日志的实时监控和告警,主要优势:
- 实时性强:基于Promtail的metrics阶段,无延迟监控
- 配置灵活:支持正则表达式灵活匹配日志内容
- 集成便利:与现有Prometheus监控体系无缝集成
- 可扩展性:支持虚拟机和K8s两种部署方式
通过该方案,可以有效提升生产环境异常发现的及时性,降低业务风险。
参考文档