一次线上Redis集群节点主从切换引起的应用重启问题排查处理
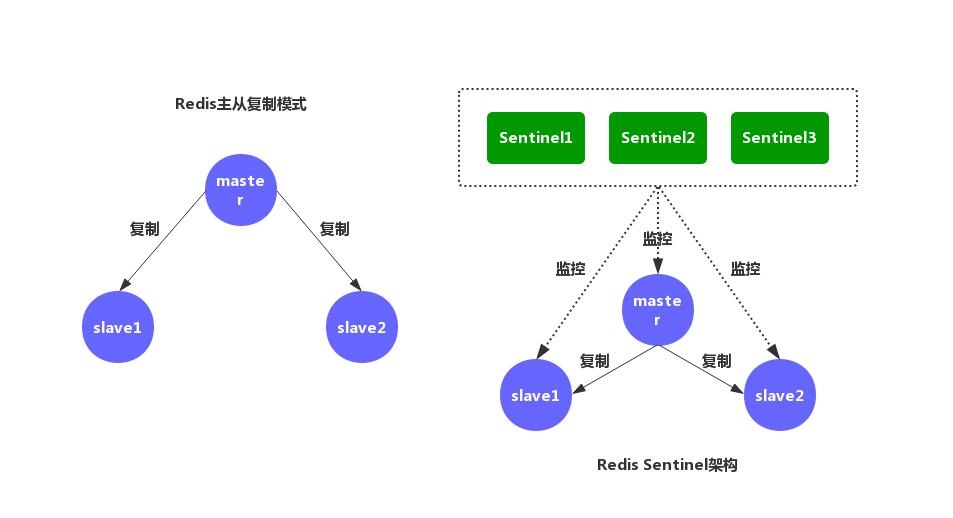
一、问题背景
某日生产环境出现大规模应用重启告警,经过初步排查发现与Redis集群节点主从切换有关。该问题导致多个核心服务不可用,对业务产生了较大影响。
问题环境:
- Redis集群架构
- Kubernetes容器化部署
- Spring Boot微服务架构
二、问题现象
问题发生时,监控系统显示大量应用实例出现重启现象,具体表现为:
- 应用层面: 多个微服务实例频繁重启
- 日志异常: 应用日志中出现大量Redis连接异常
- 监控指标: Redis集群监控显示某个节点发生主从切换
- 业务影响: 部分核心接口响应超时,用户体验下降

图1:Redis集群节点资源监控图示
三、排查过程
3.1 初步分析
通过监控系统初步定位,发现问题与Redis集群节点主从切换存在强关联性:
- 时间关联性:应用重启时间与Redis节点主从切换时间高度吻合
- 影响范围:所有依赖该Redis集群的服务均受到影响
- 初步判断:可能是Redis集群拓扑变化导致应用无法正常连接
3.2 深入排查
为进一步定位问题根因,我们进行了深入的技术排查:
排查工具与方法:
- 查看应用日志,分析异常堆栈信息
- 检查Redis集群状态和节点信息
- 分析Kubernetes事件和Pod状态变化
- 对比切换前后集群拓扑结构
关键发现:
- 应用日志中反复出现
Node xxx.xxx.xxx.xxx:xxxx is unknown to cluster异常 - Redis集群已完成主从切换,但应用仍尝试连接已失效的节点
- K8s健康检查因Redis健康检查失败而判定Pod不健康,触发重启机制
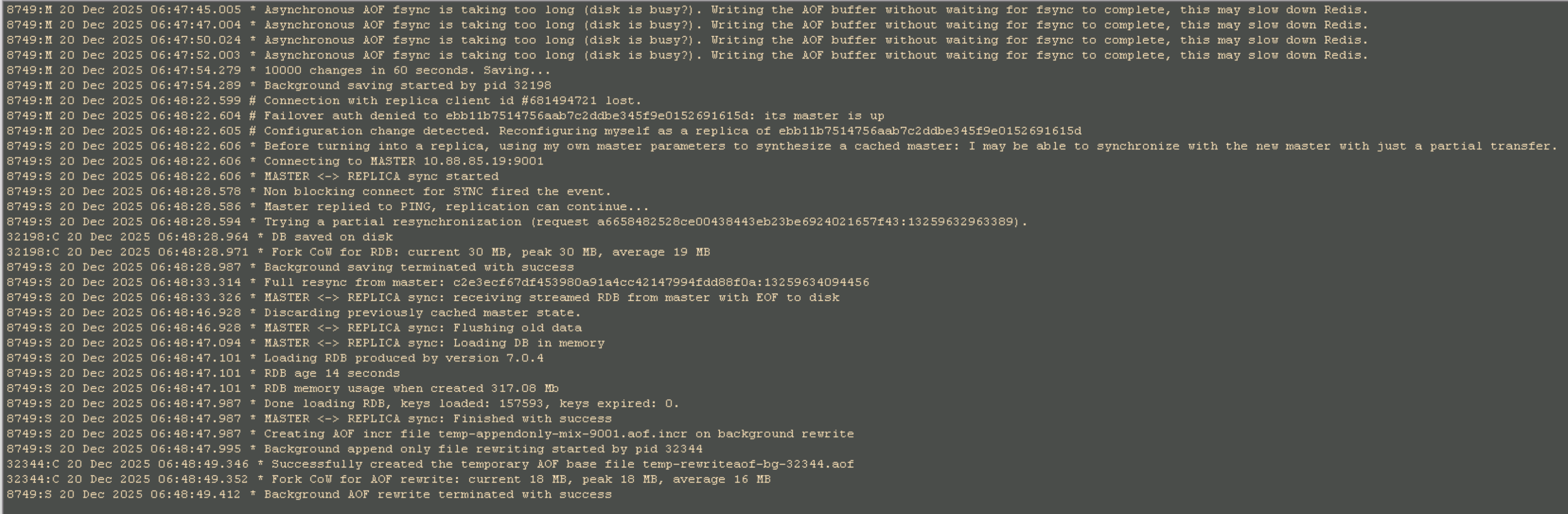
图2:Redis集群节点日志截图
3.3 根因定位
通过深入分析,我们定位到问题的根本原因:
Pod重启的核心原因分析:
Redis集群健康检查失败是触发Pod重启的直接原因,而客户端未能及时感知集群拓扑变化是问题的根本所在,二者共同导致Pod被K8s判定为”不健康”并重启:
- 直接触发原因:Redis集群健康检查失败
- 日志中反复出现Redis health check failed及相关异常:
org.springframework.dao.DataAccessResourceFailureException: Node x.x.x.x:xxxx is unknown to cluster- 含义:Spring Boot Actuator的Redis健康检查组件尝试连接Redis集群节点时,发现该节点不在集群节点列表中
- 连锁反应:K8s的存活/就绪探针因健康检查失败判定Pod不健康,进而触发Pod重启

图3:Kubernetes事件通知截图
四、问题分析
4.1 技术原理分析
Redis集群主从切换后应用持续报Node x.x.x.x:xxxx is unknown to cluster,核心原因是应用侧未感知Redis集群拓扑变化,仍缓存旧的节点信息(失效的主节点),而新的集群拓扑中已无该节点。
主从切换后Redis集群的核心变化:
- 节点角色/状态变更: 原主节点可能被下线、降级为从节点,或在集群重新分片后被移除
- 集群拓扑更新: Redis集群会将新的主节点信息同步到所有存活节点
客户端感知问题: 应用侧不会主动感知这个变化,仍依赖初始化时加载的旧拓扑。
4.2 为什么报错会”持续”?
- 缓存未过期: Jedis客户端的拓扑缓存无过期机制,除非主动刷新或应用重启,否则不会更新
- 健康检查周期性执行: K8s探针/Actuator健康检查是定时任务,每次都会尝试访问旧节点,导致报错反复出现
- 无被动刷新触发条件: 若应用访问的key哈希槽未命中该失效节点,不会触发MOVED重定向,Jedis无法被动更新拓扑
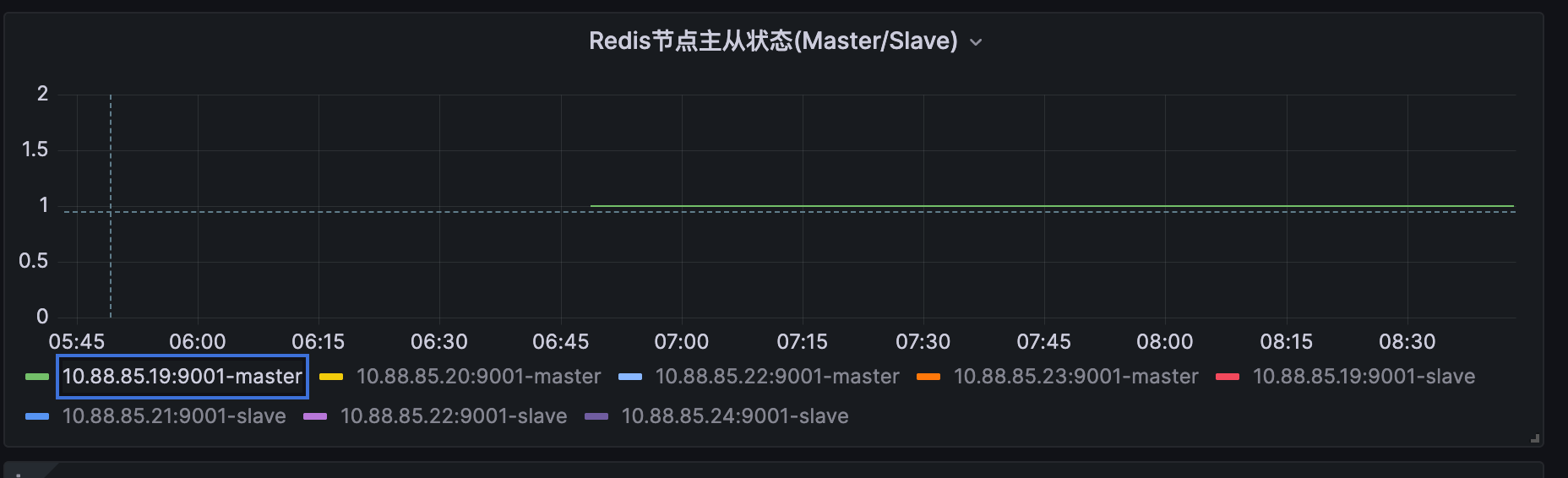
图4:Redis节点主从状态变化图示
4.3 Redis主从切换的根本原因分析
通过分析Redis节点日志和资源监控数据,我们定位到主从切换的根本原因:
关键日志分析:
从Redis节点日志中发现了以下关键信息(时间点:2025-12-20 06:47-06:48):
Asynchronous AOF fsync is taking too long (disk is busy?).
Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.这条警告在短时间内反复出现,表明Redis在进行AOF持久化时遇到了严重的磁盘IO瓶颈。
资源监控关键发现:
从CPU监控图可以清晰看到:
- 06:48:30时刻:CPU使用率突然飙升至100%
- iowait占比高达8.4%:说明系统在等待磁盘IO操作完成
- 持续时间:高负载状态持续了一段时间才恢复
主从切换触发链路:
持久化操作触发:
- 日志显示Redis正在进行RDB持久化(
1000 changes in 60 seconds. Saving...) - 同时进行AOF重写操作(
Background saving started by pid 32198) - 创建临时AOF文件(
temp-rewriteaof-bg-32344.aof)
- 日志显示Redis正在进行RDB持久化(
磁盘IO瓶颈:
- AOF fsync操作耗时过长,磁盘处于繁忙状态
- Fork操作的Copy-on-Write机制加剧了内存和IO压力
- 日志显示Fork CoW达到30MB,峰值30MB
主节点响应缓慢:
- CPU资源被持久化操作大量占用(100%使用率)
- 主节点无法及时响应从节点的心跳请求
- 从节点认为主节点不可用
集群自动故障转移:
- 日志显示:
failover auth denied to edb11b7514756aab7c2ddbe345f9e015269161Sd: its master is up - 随后进行配置变更:
Configuration change detected. Reconfiguring myself as a replica - 最终完成主从切换:
MASTER <-> REPLICA sync started
- 日志显示:
根本原因总结:
此次主从切换的根本原因是Redis持久化操作(RDB+AOF重写)在高负载情况下触发了严重的磁盘IO瓶颈,导致:
- 主节点CPU和IO资源被大量占用
- 主节点无法及时响应集群心跳
- 从节点判定主节点失效,触发自动故障转移
- 集群执行主从切换以保证高可用性
这是Redis集群在面对持久化压力时的正常自我保护机制,但由于应用侧未能及时感知拓扑变化,导致了后续的应用重启问题。
五、解决方案
5.1 临时解决措施
紧急修复:重启应用
重启受影响的应用实例,使其重新从Redis集群种子节点加载最新拓扑,直接解决缓存旧节点的问题。这是一种有效的应急处理措施,可以快速恢复服务。
5.2 根本解决方案
长期优化:开启Jedis集群拓扑自动刷新
修改Spring Redis配置,开启Jedis的拓扑自动刷新功能,让应用能够主动感知集群拓扑变化,从根本上解决此类问题:
- 配置JedisCluster的
refresh参数 - 设置合理的刷新间隔时间
- 启用集群节点变化监听机制
- 优化健康检查逻辑,增加容错机制
5.3 方案实施
实施步骤:
配置优化:
- 在Spring Boot配置文件中启用Jedis集群拓扑自动刷新
- 调整健康检查超时时间和重试机制
- 增加重试逻辑和熔断机制
代码改造:
- 优化Redis客户端初始化逻辑
- 增加集群节点状态检测机制
- 实现优雅降级策略
测试验证:
- 在测试环境模拟主从切换场景
- 验证应用是否能正确感知集群变化
- 确认健康检查机制的稳定性
上线部署:
- 分批灰度发布配置变更
- 监控上线后的系统表现
- 准备回滚方案
六、经验总结
通过本次问题处理,我们得到了以下经验教训:
6.1 避免类似问题的措施
应用层面:
- 客户端优化: 启用Redis客户端的集群拓扑自动刷新功能
- 健康检查改进: 优化健康检查逻辑,增加容错和重试机制
- 配置管理: 建立完善的配置管理机制,确保关键参数正确设置
Redis层面:
持久化优化:
- 调整AOF重写触发条件,避免与RDB同时执行
- 配置
no-appendfsync-on-rewrite yes,在重写期间不执行fsync - 考虑使用Redis 7.0的Multi-Part AOF特性
资源规划:
- 确保Redis服务器有足够的CPU和IO资源
- 使用SSD磁盘提升IO性能
- 合理配置
maxmemory参数,避免Fork时的内存压力
持久化策略:
- 根据业务特点选择合适的持久化策略(RDB/AOF/混合)
- 错峰执行持久化操作,避开业务高峰期
- 考虑在从节点进行持久化操作
6.2 监控告警改进建议
- 增加专项监控: 监控Redis集群节点变化事件
- 完善告警策略: 区分瞬时故障和持续异常
- 建立关联分析: 关联Redis集群状态与应用健康状态
6.3 应急预案完善
- 标准化处理流程: 制定Redis集群故障应急处理手册
- 自动化恢复机制: 开发自动检测和恢复脚本
- 定期演练: 定期进行故障恢复演练
七、参考资料
- Redis官方文档 - 集群规范
- Spring Data Redis官方文档
- Jedis客户端使用指南
- Kubernetes健康检查最佳实践
- 微服务架构下的故障处理模式