一次生产数据库CPU高占问题排查处理
背景与现象
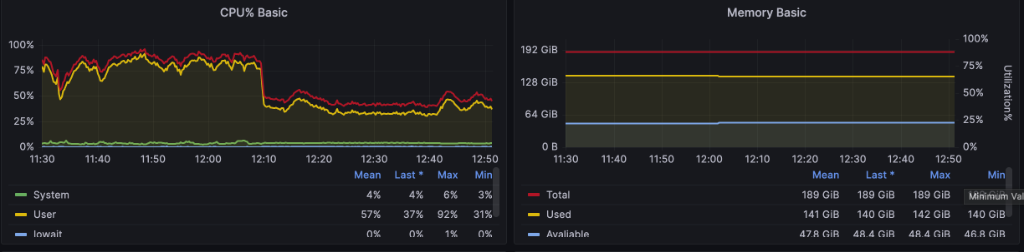
业务侧报警提示数据库 CPU 持续飙高(User 态接近 80%-90%),内存平稳无异常,磁盘 iowait 低。观察监控后确认在 11:30-12:05 期间 CPU 居高不下。
快速定位
首先排除系统层 I/O 或内核问题,转向 MySQL 层确认 InnoDB 事务与锁等待情况:
SELECT
t.`trx_mysql_thread_id`,
t.trx_id,
t.trx_state,
t.trx_started,
t.trx_query
FROM information_schema.innodb_trx t
ORDER BY t.trx_started ASC
LIMIT 5;查询显示存在一个明显的长事务(trx_state=RUNNING,trx_started 很早):

从截图可见该事务在 2026-03-04 04:58:07 就已开始,且 trx_query 为 NULL,结合现场判断为空闲但未提交的“长事务”(Idle in transaction)。通过 SHOW PROCESSLIST/performance_schema 进一步关联应用侧连接后,确认来源为统计模块的定时统计/报表任务。
机理说明
长事务会长期持有一致性读视图,阻止历史版本(undo 页)及时清理,导致:
- Purge 线程清理效率下降,历史版本累积,带来额外的 CPU 消耗;
- Buffer Pool 命中与页维护成本升高,整体吞吐下降但 CPU 占用上升;
- 在并发读写下,内部维护开销(元数据、版本链遍历)进一步放大。
由于 iowait 较低而 User 态较高,符合“长事务导致 InnoDB 内部维护与计算开销偏高”的特征。
处置过程
- 与业务沟通确认可中断该会话(统计模块定时任务),并在调度侧暂时暂停该任务。
- 根据
trx_mysql_thread_id终止连接:-- 建议先 SHOW PROCESSLIST 或 performance_schema 确认线程 KILL <trx_mysql_thread_id>; -- 或显式断开连接 KILL CONNECTION <trx_mysql_thread_id>; - 终止后 CPU 迅速回落至正常区间,业务恢复稳定(见上图)。
问题定位
根据长事务的开始时间,怀疑是统计模块的定时任务触发了该长事务,查看统计模块监控数据。
统计模块JVM监控
问题分析
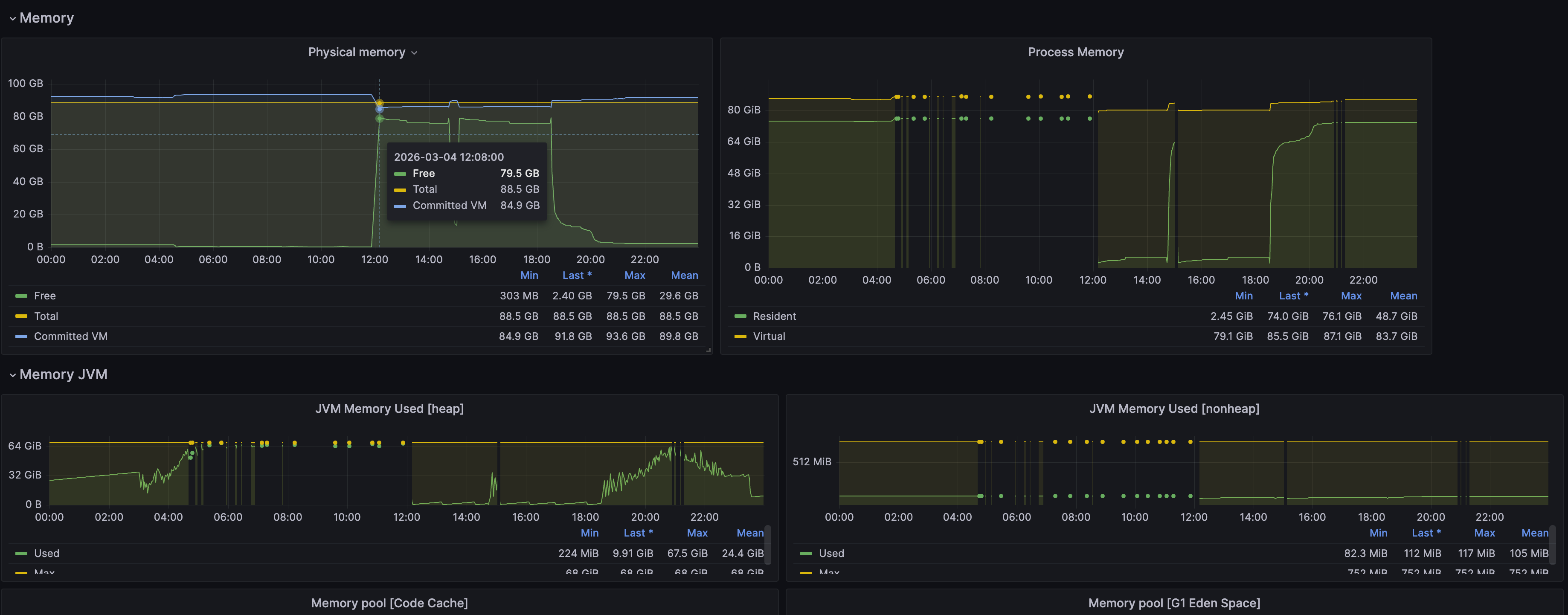
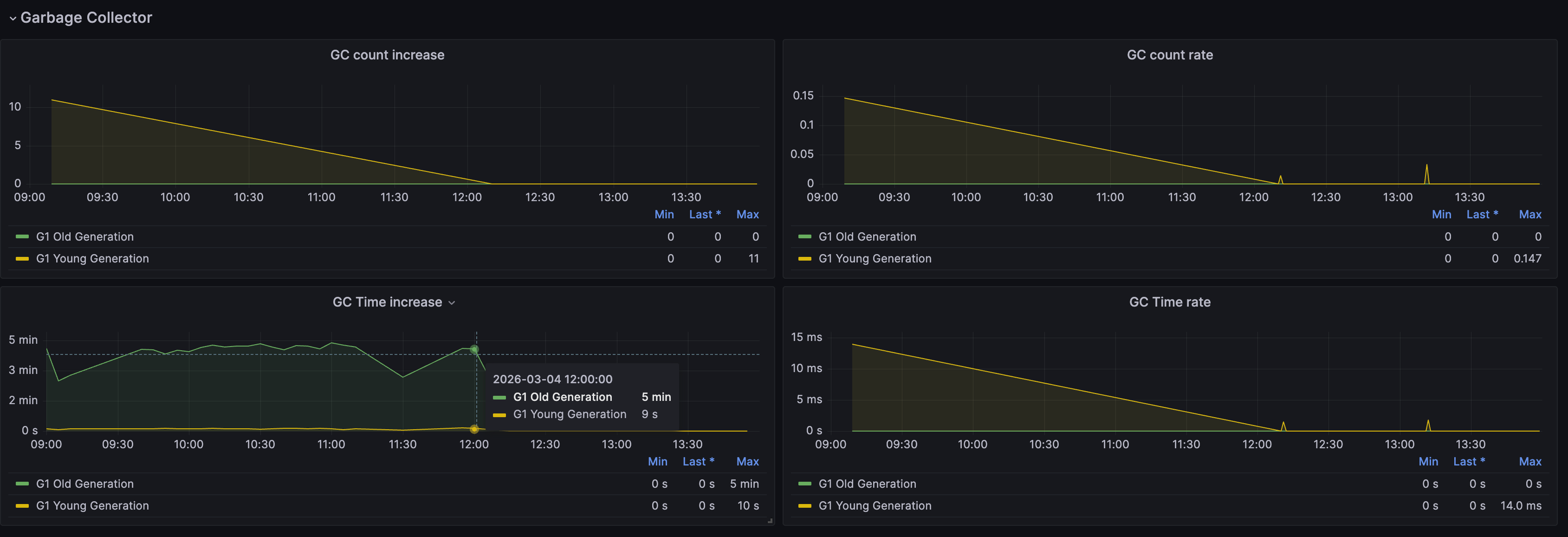
根据统计模块JVM监控数据,统计模块堆内存占用接近堆内存最大上限,同时老年代 GC 平均耗时约 280秒,意味着在每 5 分钟(300秒)的时间窗口内,老年代 GC 占用了约 56% 的时间。
结论
统计模块GC 耗时占比高达 93% 以上,CPU 几乎全部在做垃圾回收,业务线程几乎完全停顿(Stop-The-World)。
复盘与预防
统计问题分析
分析统计模块的业务逻辑,由于业务数据量过大,分表后的单表数据量接近一亿,统计模块没有直接在数据库进行数据统计,而是将数据库拉取的应用内存中进行计数统计且需要对近3天的数据进行统计;同时为了提高统计效率,使用多线程技术并发进行数据拉取统计,最后将统计结果合并。
由于近2日业务数据量增加,统计模块分配的内存空间不足,统计模块一直在做GC,而统计未完成内存无法释放,统计模块在持续GC触发了长事务,导致CPU占用过高。
统计模块专项治理
该统计模块功能已通过大数据平台的功能进行替代,但部份功能需要进行迁移验证;临时解决方案是控制统计模块的并发线程数,避免内存不足导致GC触发长事务。
说明:目前统计模块的堆内存分配为68G,物理主机内存为88G,且后业务数据量不可控,所以暂不考虑对统计模块堆内存进行调整。
小结
本次 CPU 高占由统计模块的长事务引发。通过定位 InnoDB 事务并终止异常会话后,CPU 立即回落。根因在于近期业务量突增,统计模块内存空间不足导致JVM在持续GC,持有会话不能提交,导致长时间占用一致性读视图。